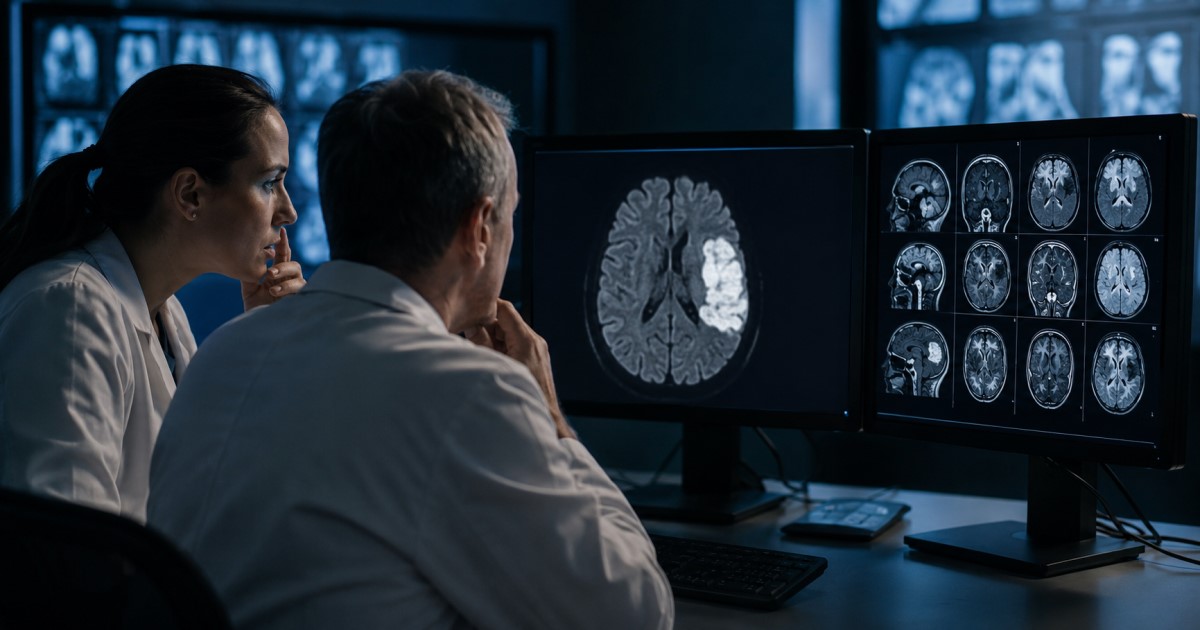
AI can look useful in narrow care tasks
Did you know? Claude-3.0 and ChatGPT-4o achieved 100% accuracy in pediatric medication dosage calculations and were faster than nurses.
This is a strong practical signal, but it applies to a narrow task — not autonomous clinical care.